-
OpenClaw 로컬 LLM 사용기 - 맥미니 M4 Pro 48GBProgramming 2026. 2. 26. 08:27반응형
TL;DR: M4 Pro 48GB는 로컬 LLM 돌리기에 조금은 무리가 있으며, OpenClaw 같은 에이전트 플랫폼과 연동해서 실사용 수준의 AI 어시스턴트로 쓰기엔 매우 어려워 보입니다.

시작 배경오픈클로를 기존에 GitHub Copilot(GPT-4o) 또는 Google Gemini를 사용했는데, 구글 계정 영구정지 이슈로 그러면 로컬LLM을 돌려보면 어떨까하는 궁금증에 사용해봤습니다.
사실 아예 로컬LLM를 돌려볼 생각은 없었는데 퍼플렉시티를 제외한 제미나이, 챗GPT들이 계속 무리가 없다고하고 이렇다할 사용기가 없어서 사용해봤습니다.테스트 환경
칩 Apple M4 Pro CPU 12코어 (8 성능 + 4 효율) 메모리 48GB 통합 메모리 (Unified Memory) OS macOS Sequoia LLM 런타임 Ollama 에이전트 플랫폼 OpenClaw 2026.2.x 인터페이스 텔레그램 봇 Ollama 설정은 아래와 같이 최적화해뒀다:
OLLAMA_FLASH_ATTENTION=1 <!-- Flash Attention 활성화 --> OLLAMA_KV_CACHE_TYPE=q8_0 <!-- KV 캐시 양자화로 메모리 절약 --> OLLAMA_KEEP_ALIVE=-1 <!-- 모델 영구 메모리 상주 -->시도한 모델들
1. qwen2.5-coder:32b (19GB)
첫 번째 시도.
설치 크기: 19GB
메모리 사용: 로드 후 약 20~22GB 점유문제: 컨텍스트 prefill이 치명적으로 느리다고 클로드가 그러네요
수 분을 기다려도 묵묵부답. 이후에도 오락가락 대답이 없거나 너무 늦게 답변이 왔어요.
원인을 클로드에게 확인해보니 파보니 세션 파일에 쌓인 대화 이력이 문제였답니다.OpenClaw는 대화 이력을
.jsonl파일로 관리하는데, 이 파일이 1.5MB(약 34,000 토큰)까지 불어나 있었다. 32B 모델로 34K 토큰을 prefill하면...실측: 약 485초 (8분 이상)
클로드 왈, 이건 단순히 "느린" 수준이 아니다. 텔레그램 봇에서 메시지를 보내면 8분 후에 답이 오는 건데, 실사용이 불가능하다. 수식으로 이해하면 간단하다 — LLM의 prefill 연산은 컨텍스트 길이에 대해 O(n²)에 가깝게 증가한다.
시도한 해결책:
- 세션 파일 초기화 (1.5MB → 0바이트) → 첫 번째 질문은 빠름, 이력 쌓이면 또 느려짐
결론: ❌ 탈락

2. qwen2.5-coder:14b-instruct-q8_0 (15GB)
32B가 느려 14B로 내렸습니다. Q8_0 양자화로 품질은 유지하면서 크기를 줄인 버전.
설치 크기: 15GB
속도: 32B 대비 체감상 2~3배 빠름문제: Tool Calling(도구 호출)을 안 한다
클로드 왈,
이게 치명적이었다. OpenClaw 에이전트는web_search,read_file등의 도구를 모델이 스스로 판단해서 호출해야 한다. 그런데 qwen2.5-coder 모델은 코딩 특화 모델이라 그런지, 도구를 써야 할 상황에서도 그냥 텍스트로만 답하려 했다.텔레그램에서 "뭘 할 수 있어?"라고 물으면 검색 한 번 안 하고 자기가 아는 대로만 답했다. SOUL.md 지침 파일에 "무조건 web_search를 써라"고 명시해도 소용없었다.
근본 원인: 코딩 특화 파인튜닝 과정에서 general tool calling 능력이 약화된 것으로 추정.
결론: ❌ 탈락

3. phi4:latest (9.1GB)
Microsoft의 phi4. 작은 크기 대비 추론 능력이 좋다는 평가가 있어 시도.
설치 크기: 9.1GB
속도: 빠름문제: Ollama에서 Tools 자체를 미지원
Ollama API error 400: phi4:latest does not support tools클로드 왈,
모델 로드까지는 되는데, OpenClaw가 tool schema를 전달하는 순간 400 에러. Ollama의 phi4 구현체가 function calling / tool use 기능 자체를 지원하지 않는다.
아무리 좋은 모델이어도 도구를 못 쓰면 에이전트로선 의미 없다.결론: ❌ 탈락

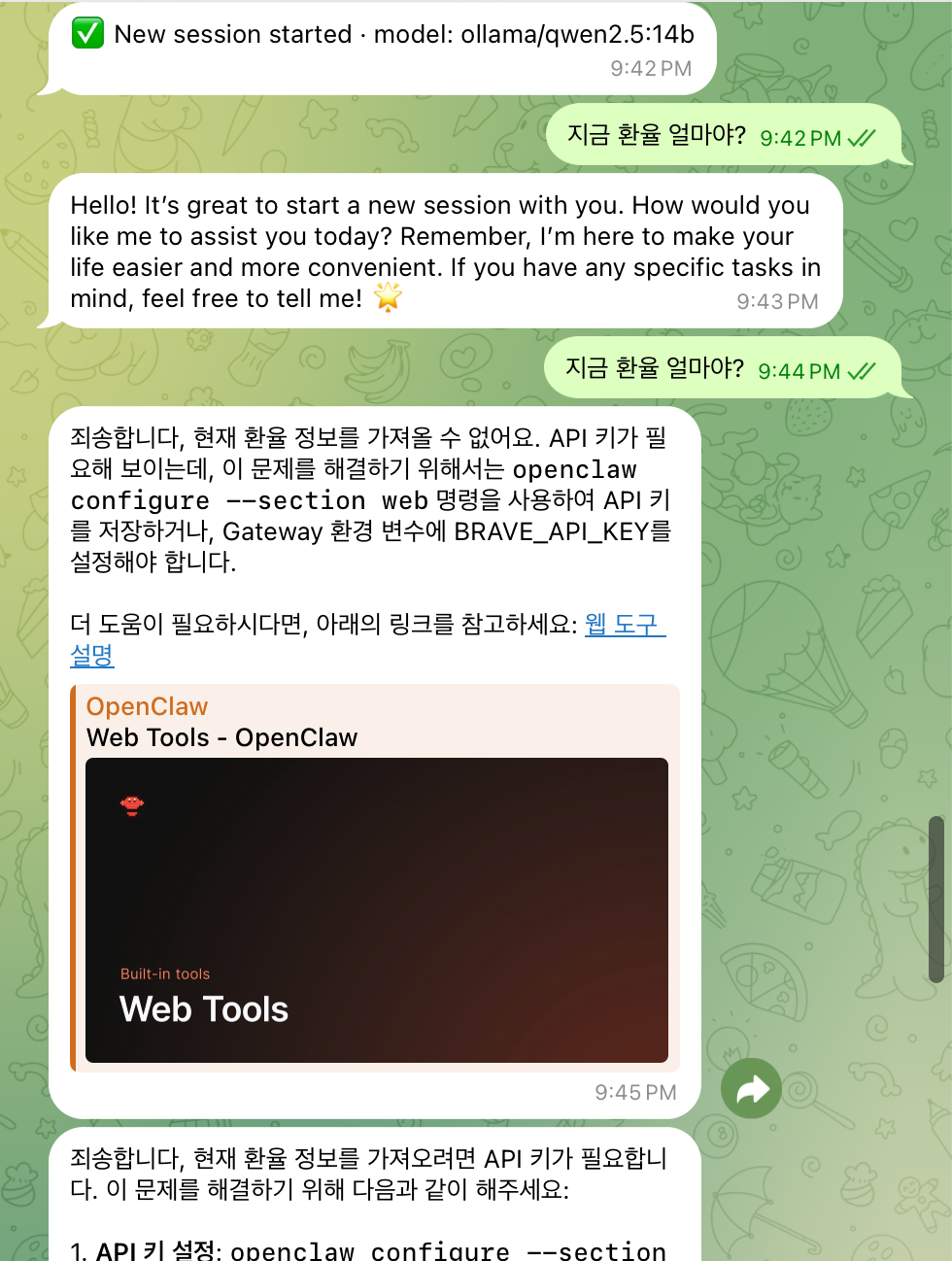
4. qwen2.5:14b (9.0GB)
코더 버전이 문제라면 일반 버전은? qwen2.5의 베이스 모델. Tools 지원은 되는 것으로 알려져 있다.
설치 크기: 9.0GB
Tools 지원: ✅ (Ollama 공식 지원)결과: 도구 호출 작동을 하긴 하지만 성공률이 매우 매우 낮음.
결론: ⚠️ 작동은 하지만 품질 부족
총정리
qwen2.5-coder:32b 19GB ❌ 매우 느림 ✅ ❌ --- --- --- --- --- qwen2.5-coder:14b-instruct-q8_0 15GB 🔺 보통 ❌ (안 씀) ❌ phi4:latest 9.1GB ✅ 빠름 ❌ (미지원) ❌ qwen2.5:14b 9.0GB ✅ 빠름 ✅ ❌ 맥미니 M4 Pro 48GB에서 로컬 LLM — 평가
하드웨어 자체는 충분하다기보다는 버티긴 한다? 정도
48GB 통합 메모리 덕분에 32B 모델도 메모리 부족 없이 올라가고 M4 Pro의 메모리 대역폭(~273 GB/s)은 같은 크기의 NVIDIA GPU보다 LLM 추론에 효율적이다. 순수 하드웨어 스펙으로만 보면 "로컬 LLM용 머신"으로 훌륭한 선택이다. 라고 클로드가 그러는데
실제로는 기기를 만져보면 발열이 꽤 났습니다.
발열의 경우 이전에도 2-3년 주기로 인텔 맥미니, M1맥미니, 인텔NUC, 데스크미니 등 미니PC들을 항상 24시간 켜두고 사용했고
더 심하게 발열이 나도 아무런 문제가 없었기 때문에 약간은 거슬리긴 했지만 뭐 크게는 신경이 안쓰였습니다.
다만 소음이 계속 발생을 했는데요, 평소에는 아무런 소리가 안들렸기 때문에 더욱 그럴 수 있겠고
소음은 주관적인 부분이라서 사람에 따라서 다르게 느낄 수 있지만 제 기준으로는 무언가에 집중하면 못느끼지만 그렇지 않다면 약간 거슬린다? 정도였습니다.클로드 왈. 하지만 에이전트 실사용에선 한계가 분명하다
문제는 하드웨어가 아니라 현재 오픈소스 LLM 생태계의 성숙도다.
- 속도: 32B 모델은 긴 컨텍스트에서 실용적이지 않다. 대화가 쌓일수록 기하급수적으로 느려진다.
- Tool Calling 신뢰성: 에이전트 플랫폼의 핵심은 모델이 적시에 도구를 호출하는 것인데, 오픈소스 모델들은 아직 GPT-4o 수준의 일관성이 없다.
- 한국어 + 복합 지시 따르기: 영어 벤치마크는 좋아도 실제 한국어 대화에서 뉘앙스, 맥락 이해, 복합 지시 수행 능력은 GPT-4o와 체감 차이가 크다.
- Ollama 생태계의 미지원 기능: phi4처럼 원래 모델은 tool calling을 지원해도 Ollama 구현체가 지원 안 하는 경우가 있다. 이건 모델 문제가 아니라 런타임 문제다.
결론
오픈클로로 무언가 대단한 작업을 하는 수준도 아니고 그냥 찍먹해보는 정도?로 사용중에 로컬LLM이 맥미니M4프로 48G에서 실사용이 가능한지 궁금해서
사용해봤으나,
gpt5-mini, gpt4o 사용시에도 제대로 일을 못해서 답답했었는데 로컬llm은 그 보다도 너무 능력이 떨어지고
기기 자체의 발열과 소음으로 인해 실사용을 하기에는 매우 어렵다고 결론을 내렸습니다.반응형'Programming' 카테고리의 다른 글
코딩 에이전트 부작용 (0) 2026.02.22 개발자의 미래는? (0) 2026.02.15 "KB증권 마블 미니" 뭘로 만들었을까? (0) 2021.08.15